
Release Note: 5.1.23

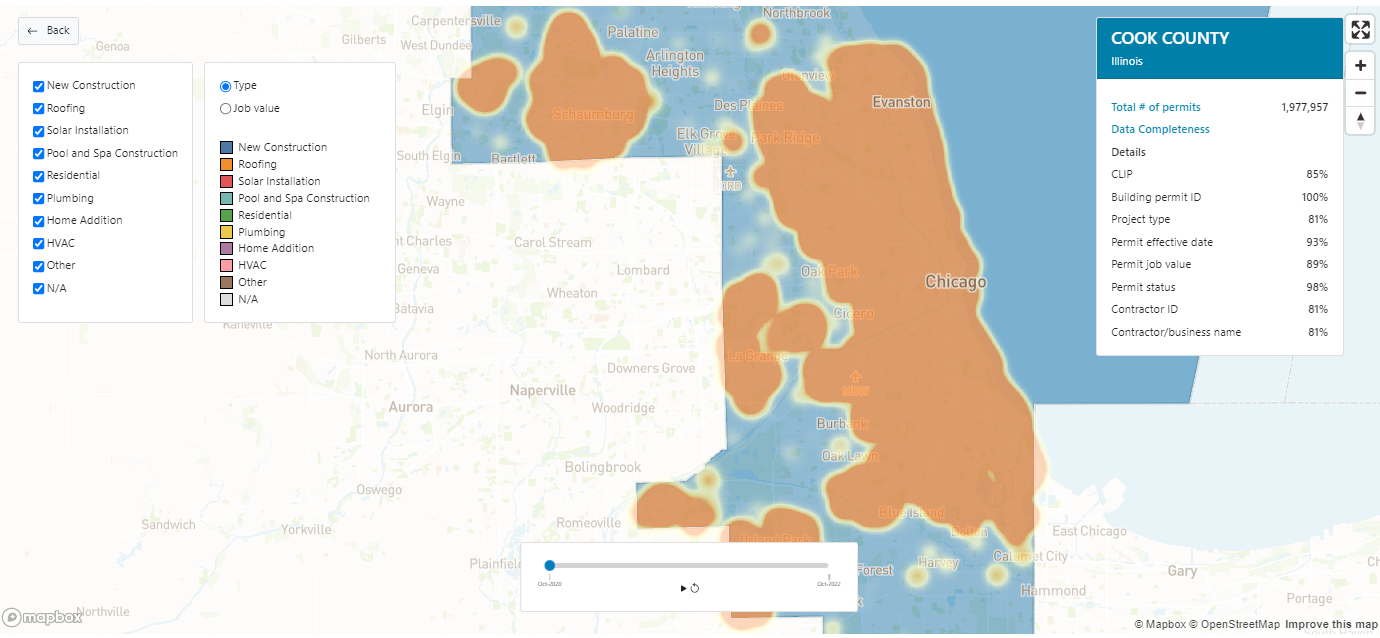
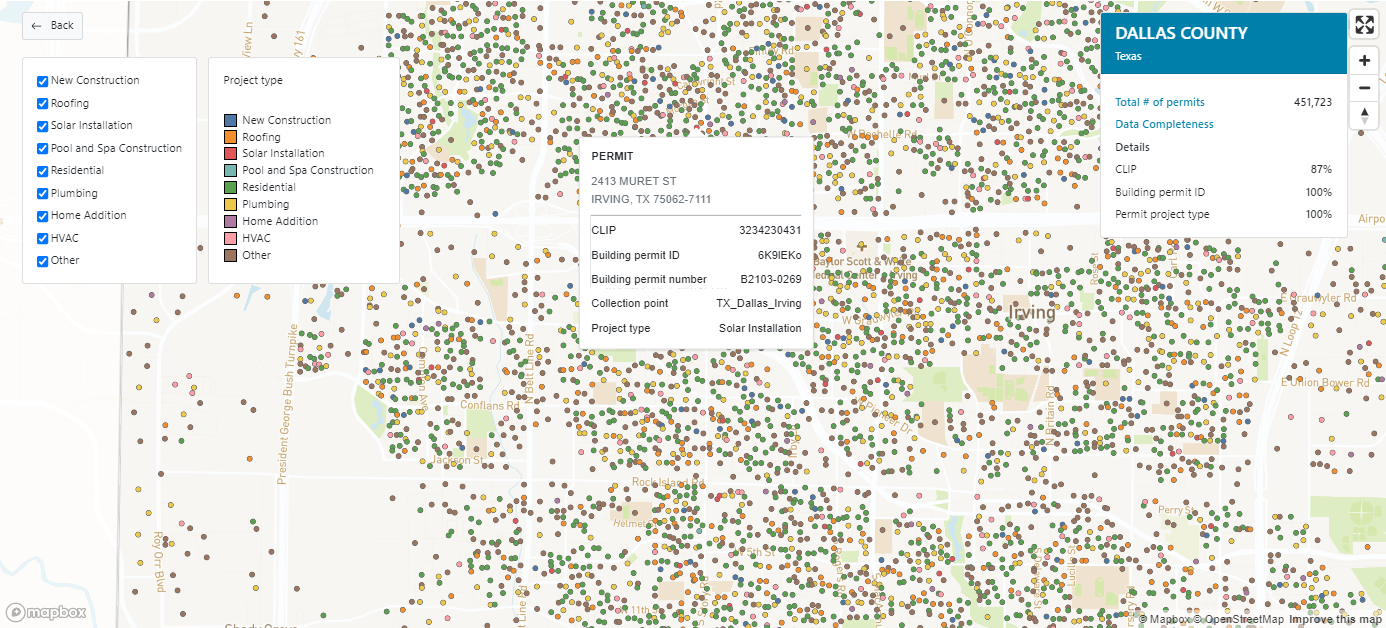
Building Permit Status History - V2 |DS101em
Building Permit Status History delivers all permit status history records and corresponding effective dates related to a building permit.
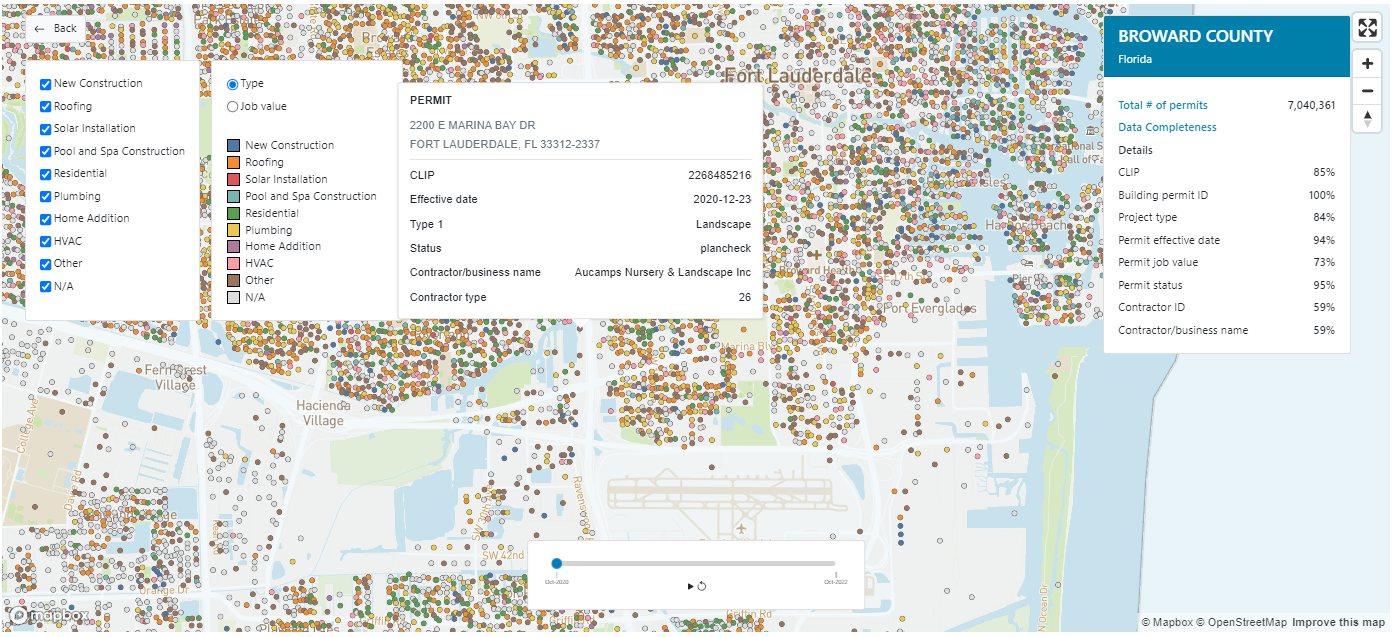
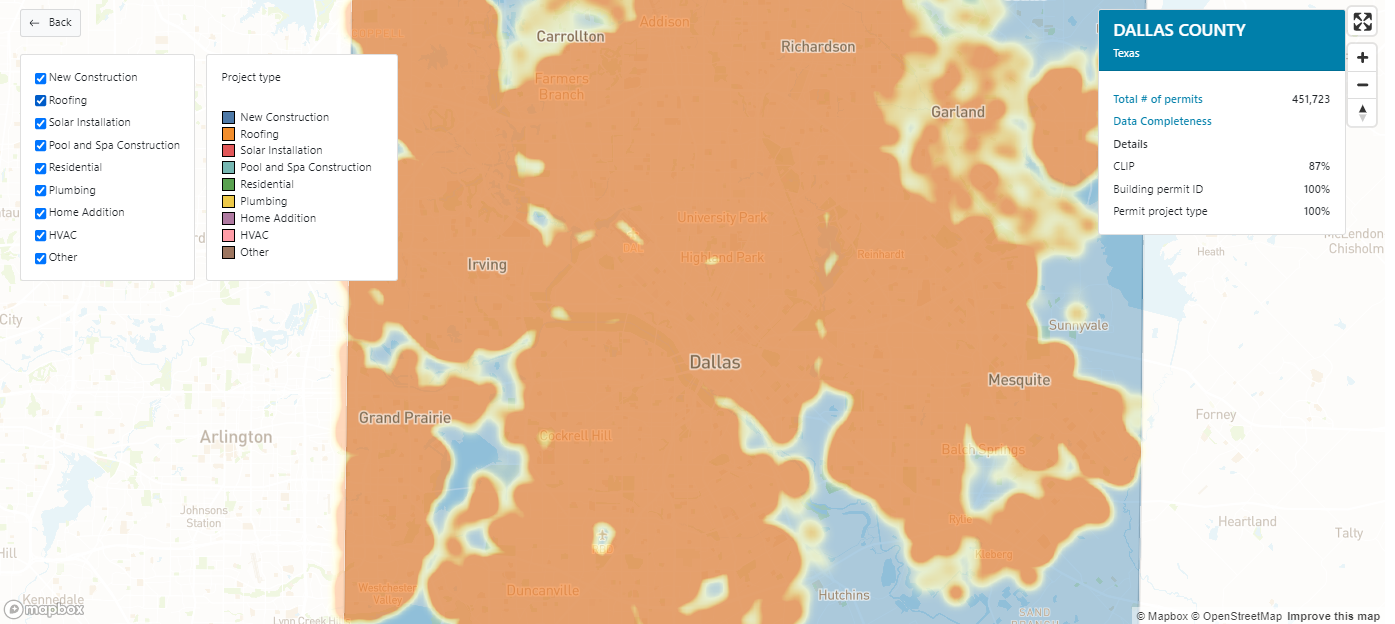
Building Permit Projects – V2 | DS102em
Building Permits Projects delivers all permit project records related to a building permit.
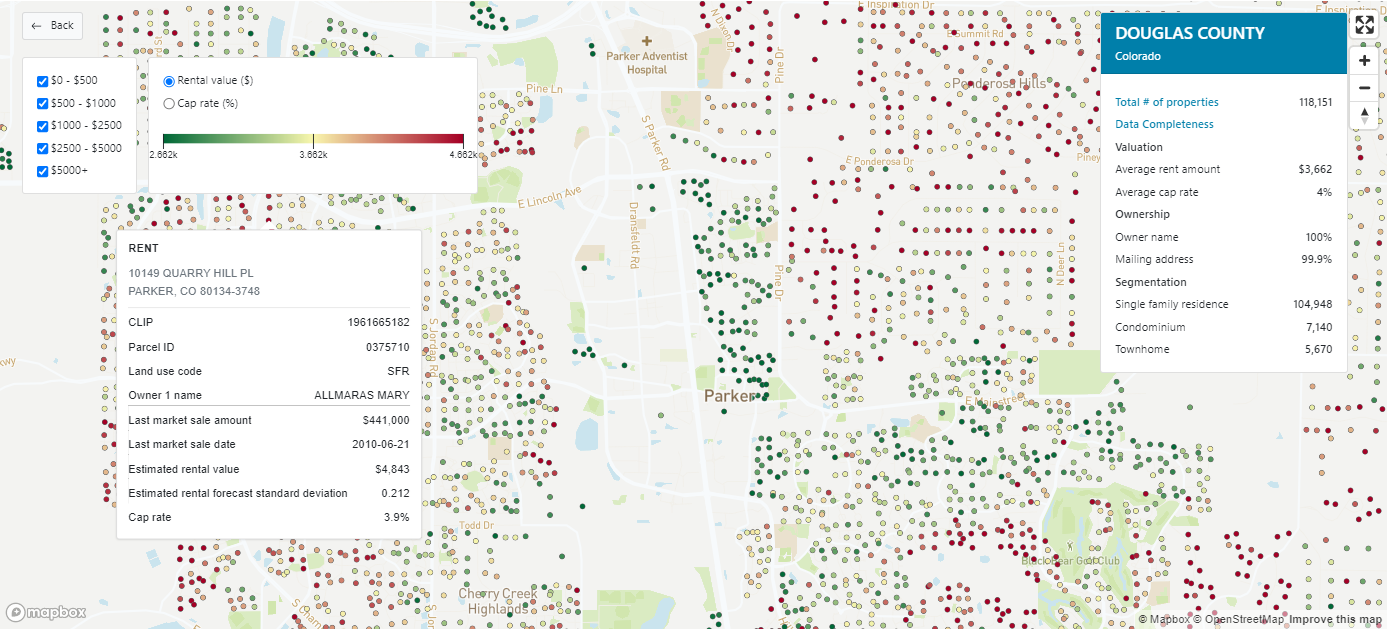
Rent Amount Model - V1 | DS75em
Rent Amount Model delivers an estimated monthly rental value that can be charged for a specific residential property, helping investors make informed property decisions.
New Features
Data Product Deletion
With our new release, Data Product deletion is now possible. Depending on the data product relationships that exist, there are three paths a user can take delete a data product:
Where active subscriptions exist, users must expire all subscriptions to enable deletion.
Where Engineered or Automated Data Product relationships exist, users must contact support to manage these relationships so that there are no longer dependent relationships to prevent deletion.
Where no active subscriptions, Engineered or Automated Data Product relationships exist, but Spaces, Export, Task or Code Asset relationships exist, deletion is immediately possible, but the user is informed of the consequences of deletion and must acknowledge and accept them to proceed.
Spaces will be Locked
Exports will be Disabled
Code Assets could Fail
Task runs could Fail
Along with the ability to delete a product comes a delete button. You will find this button contained in:
The published data products view – bottom right of page
The data product relationship view – top right of page
Spaces Containing Deleted Data Products Will be Locked
Once a Space contains a deleted data product, the space will be locked. The User Interface provides information to all Space collaborators that the deleted data product must be removed from the Space spec by the owner to unlock the Space.
Exports With Deleted Data Products Will be Disabled
When an export uses a deleted data product, the export will be disabled. No new data exports can be run, and the export will present a disabled status. The export owner still has access to the last exported data that is available, either on an endpoint or via a manual download.
Improved Error Messaging for Greater Efficiency
To improve the user experience, we’ve changed the error messages that appear for common user errors when publishing and updating data products. These messages allow users to identify and fix simple problems themselves rather than having to raise support tickets.
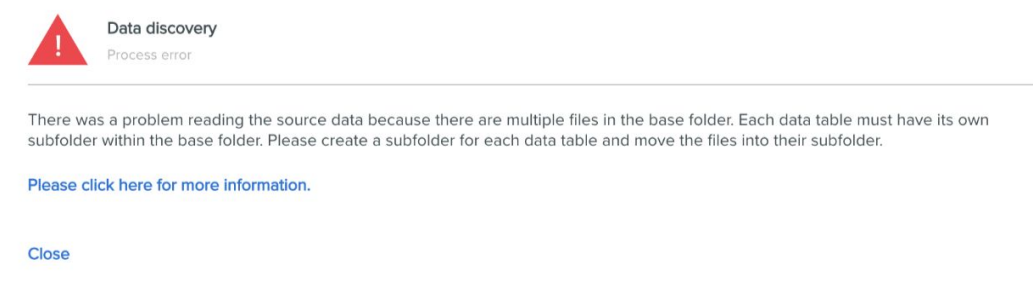
When you are publishing a new data product but have specified a location with multiple files in the base folder, you will see this error at the data discovery stage:
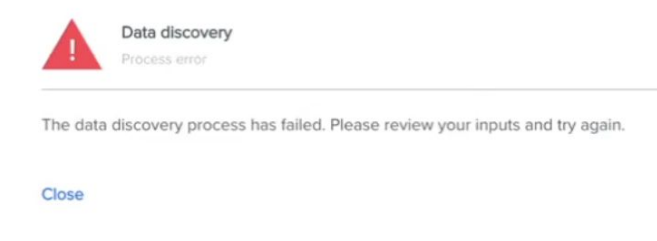
2. When you are publishing a new data product but have specified a location with no files, you will see this error at the data discovery stage:
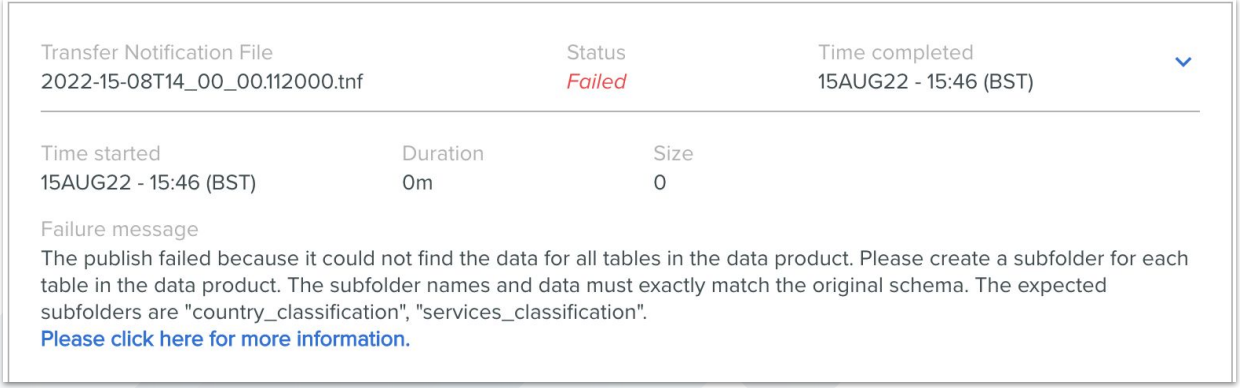
3. When you have set up a repeating publish and triggered an update with a TNF file but have not correctly created a folder for every table in your data product, you will see this error in the data product update history:
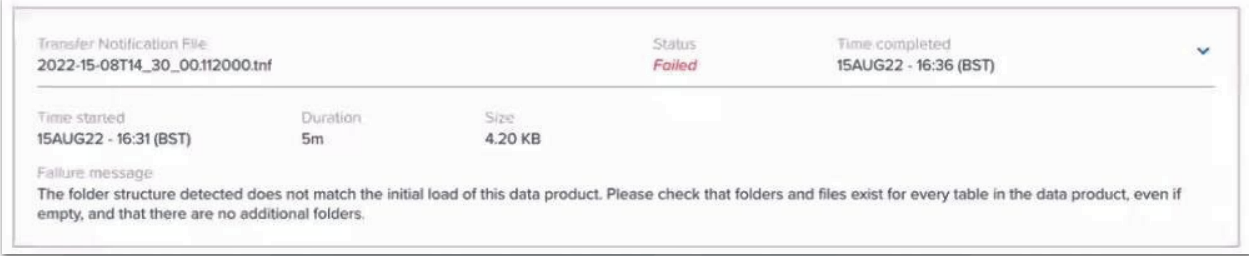
4. When you have set up a repeating publish and triggered an update with a TNF file and created a sub-folder for each of your products, but left one or more of the sub-folders empty, you will see this error in the data product update history:
5. When you have set up a repeating publish and triggered an update with a TNF file, and you have created a sub-folder for each of the products, but you have left all the sub-folders empty, you see this error in the data product update history:

Improved Organization Administrator Overview
Managing your Organization just got easier with improved access in the Organization Administration page. Org. Admins can now view all their Organization’s Subscriptions, Engineered Data Products and Automated Data Products with Data Product Relationship Tabs. This information can help with Organization and Data Product management, as well as simplifying viewing relationship dependencies before deleting a product.
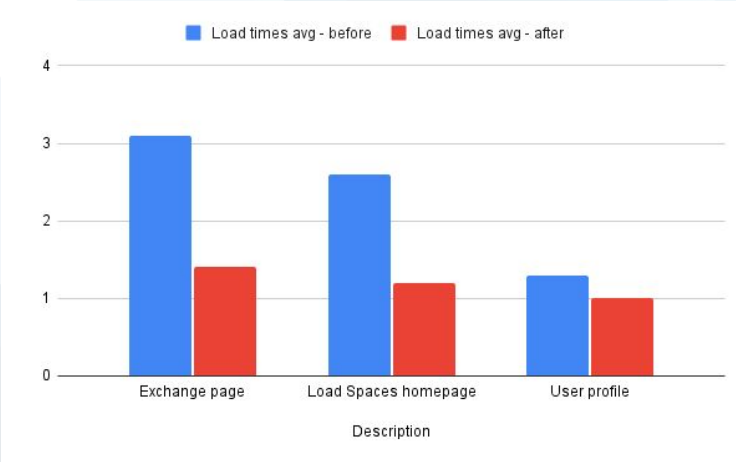
UI Performance Improvements
New performance improvements have reduced page load times, on average, by 40% across the following pages:
Enabling Presto Query Engine Within Spaces
Presto/Trino is an open source, distributed SQL query engine that can provide high levels of performance when querying large data sets. Presto has been enabled within Spaces to offer an additional query engine, providing users with up to 10x faster query times compared to HIVE’s query engine, while maintaining the familiar Spaces user experience. To utilize Presto within a Space, follow the simple approaches outlined below. Points of Note:
The Presto tool is now available in Spaces (including existing spaces.)

Currently Presto cannot be used within Tasks.
The HIVE query engine and Spark analytics configurations are maintained alongside this new component.
HIVESQL and PrestoSQL are broadly comparable, but there may be some variation in complex query capabilities.
Presto will only be enabled for current generation Spaces; it will not be available in Spaces with
“- Compatibility” or “(Legacy)” in the Space Type name. Please reach out to CoreLogic for help migrating to the new generation of Spaces.
It may be necessary to increase the physical spec of the Spaces cluster to use Presto to query large datasets.
Users can enable Presto using Hue, Jupyter and Superset, but not currently with RStudio.
How to Enable Presto Using Hue
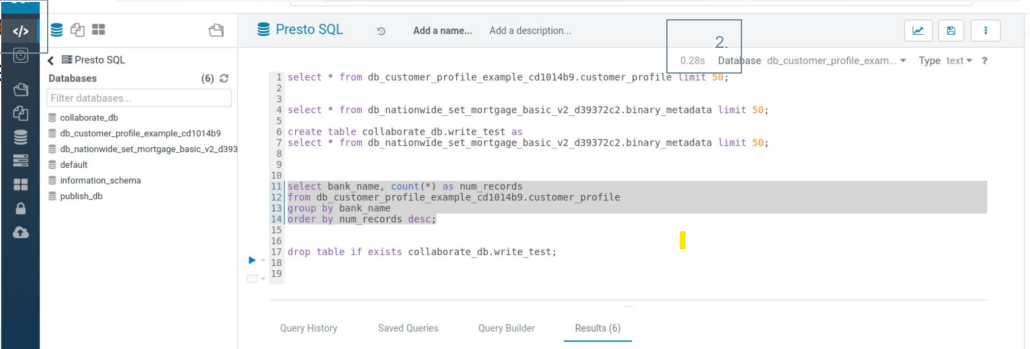
Hue-SQL Querying
After opening HUE, navigate to the PrestoSQL interpreter via the interpreter’s link on the left-hand side menu bar. Once here you can now execute SQL queries in the familiar HUE user interface (with equivalent query history, query saving, code auto-complete, etc.) while leveraging the Presto query engine for fast query execution (see 2. below).
How to Enable Presto Using Jupyter
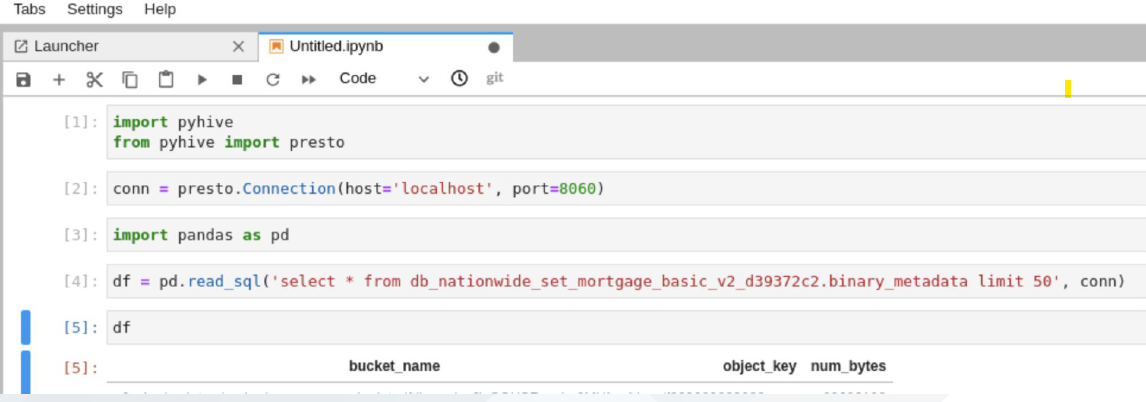
Jupyter and Python
The Presto query engine can be accessed via the pyhive library in Jupyter notebooks using the simple configuration shown below. A convenient mechanism for using this connection is to leverage the Pandas read_sql method to return the results of the Presto queries as Pandas data frames. Updated example notebooks may be provisioned with such methods.
Note: Queries that return very large volumes of data can cause instability with this method. We recommended only creating Pandas results sets with aggregated/filtered/engineered views rather than full table select queries when using large data products.
How to Enable Presto Using Superset
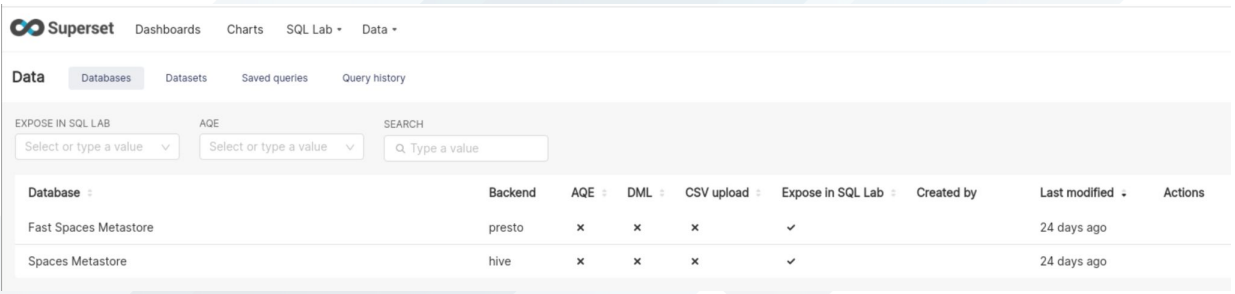
Superset
Presto is pre-configured as a Database called ‘Fast Spaces Metastore’ within Superset - as shown below. All data sets within this Database will be queried using the Presto engine when used in SQLLab and/or Charts and Dashboards, providing much improved query responses and visualization rendering. All data product tables will be automatically added to the configuration during Space activation.
Restored Partial Update Behavior for Data Products
We have restored partial update behavior when updating Data Products. When updating a product that has multiple tables but not all tables are being updated, users can select only those files that need to be updated or are new (Append). For tables that are not updated, users must create a folder but may leave it empty.
For more support, please contact customersupport@discoveryplatform.atlassian.net
© 2022 CoreLogic, Inc. All rights reserved. CORELOGIC and the CoreLogic logo are trademarks of CoreLogic, Inc. and/or its subsidiaries.
All other trademarks are the property of their respective holders.