
Using SQL in a Space
To use SQL in a Space you must:
Active a space session via your secure desktop
Select the Superset SQLLab tool icon
The core set of capabilities provided by the SQL development tools are:
Interactive query editor with auto-complete for schemas, tables, and fields
Automatically maintained query history
'Saved Queries' for persistent query storage
Query execution status monitor
Query results display (tabular and more varied views)
Create and Drop Table operations
Query Engines
In Spaces SQL can be executed via 2 query engines :
Engine | Optimised For | Known Limitations |
|---|---|---|
Trino | Fast Query performance, exploration and analytics (~ 10x faster than HIVE) Querying Remote Data Assets made added to a Space. | |
HIVE (backwards compatibility) | Bulk data processing and transformation jobs (including complex joins). SQL based Automated Tasks | Only for legacy v4 products (those that existed in v4) When running the first query of a Space session / first query in more than 15 minutes an approximately ~20second start-up time is incurred. Cannot interact with Remote Data Assets. |
Explore Data Product Structure
Each data product is available to the Space as a schema with the naming convention:
<cleansed_data_product_name>
where:
<cleansed_data_product_name> = a database compliant version of the data product name on the Exchange (e.g. spaces replaced by _, lower case etc.).
These schemas appear in the Spaces database. Spaces that have been created with multiple data products have a set of schemas available, one for each product.
Assets added directly to a space will appear inside an Assets schema in the Spaces database and are named
<cleaned_asset_name>
where:
<cleaned_asset_name> = a database compliant version of the data asset name on the Exchange (e.g. spaces replaced by _, lower case etc.).
Query Engine : Trino
To leverage the Trino query engine utilise :
Superset SQLLab : Trino Spaces data source connection
In this query engine there is a layer above the product schemas referred to as a ‘database’. All spaces will have a database named Spaces that contains the data product schemas along with the collaborate_db and publish_db space specific writeable schemas. As such SQL code can be written as :
select * from spaces.<cleansed_data_product_name>.<table name> limit 10;Clicking into the product level schema shows one or more assets from the product as tables. Data Product schema connections are read-only from within a Space.
Clicking into a table within the product level schema shows the field structure of the table, including the field data types.
Example data product presentation:
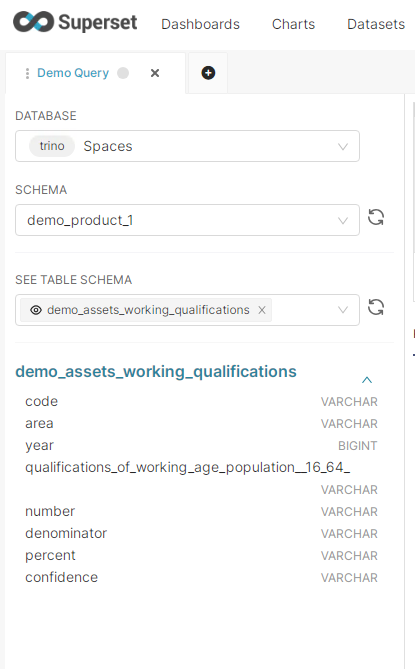
Note: If navigation windows appear empty this can be caused by browser caching auto-filling the search bars with a saved username. Clear saved username from Chrome to prevent this auto-filing behaviour and display the full extent of the Space metastore.
Run Queries
The interactive SQL editor can be used to write and execute SQL queries using standard SQL syntax:
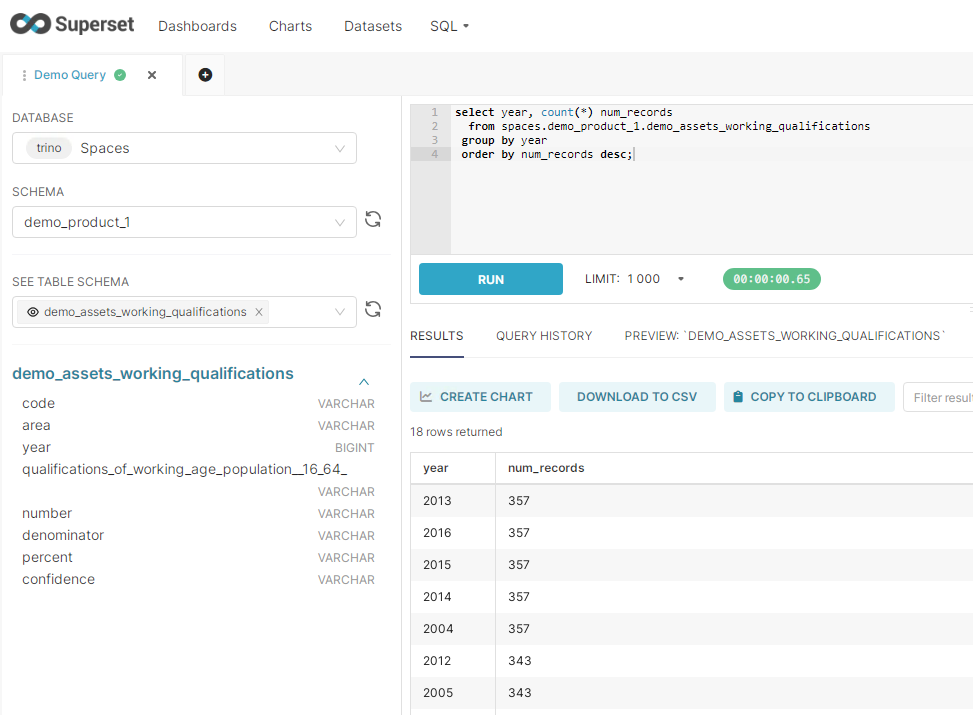
Queries can be run by clicking the RUN button with the development tool or using CTRL + Enter keyboard shortcut. Query status, progress and execution time modals are displayed as the query execution progresses.
Where larger sets of logic have been written in the query editor, specific statements (singular or a selection) can be executed by highlighting these code segments within the editor window and executing.
Detailed views of resource utilization during query execution are provided by the Space resource trackers.
When a query has completed executing results are shown in tabular form, with optional capabilities to display the results within visualizations.
The record of the query execution and results set is captured and persisted, query history persists over an extended period whereas results sets are only cached for the duration of your session. Results sets are automatically limited in length to prevent browser instability being caused by the rendering of very large record sets.
Run a CTAS query to generate and store a new output table
In addition to the read-only data product schemas, each Space is also provisioned with two read-write output locations. These locations can be used to store newly created output views from processes such as table joins, filters, aggregations and feature engineering.
The read-write locations are provisioned within the Spaces database as the two schemas described below:
collaborate_db: This schema can be used to store any output created by processes within a Spacepublish_db: This schema should be used to store output content that is intended as the source of an engineered data product or an automated data product.
These schemas are shared across all collaborators in a Space and outputs written to these locations persist across Space sessions.
Create Table As (CTAS) SQL statements can be used to create tables within these Space specific schemas.
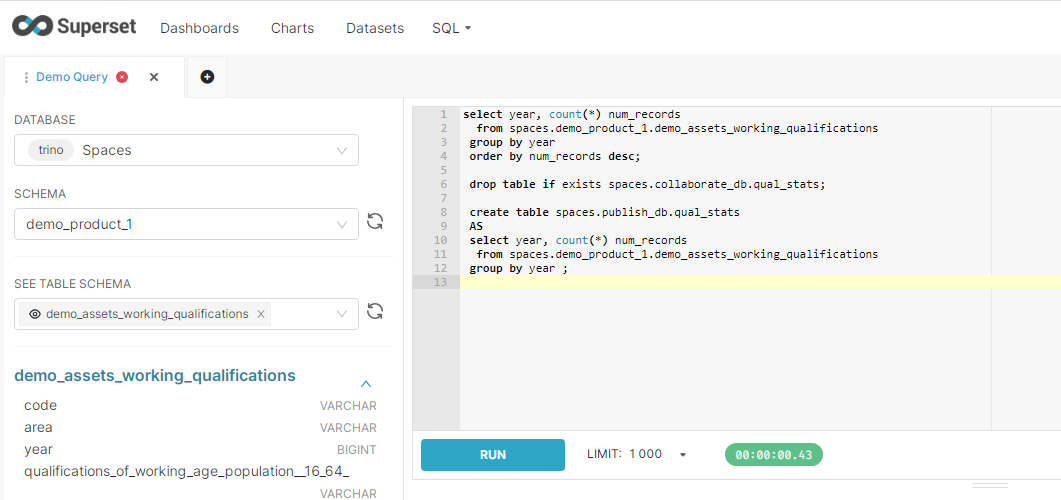
Once the query execution is complete, the output tables are displayed within the specified schema in the Spaces database in the same manner as the data product tables.
It is best practice to write queries with fully qualified table references that include the schema names to ensure accurate references across the database. It can be beneficial to include ‘drop table if exists … ' statements ahead of your CTAS statements to facilitate iterative development of logic and repeatability in automated execution through the prevention of 'output table already exists’ type errors.
CTAS statements can reference tables previously created in collaborate_db and publish_db to support multi-layered logic that utilises intermediary output.
Saving Query Documents
An in-flight record of all executed queries is maintained by the development tools.
In addition to this you can also save specific query documents within the tools as logic is finalised and validated. This can be useful for general maintenance and organization of code and developed logic, but is also a requirement if you wish to use your developed SQL within a Code Asset to allow you to create an automated data product.
Note: Saved Query Documents are shared across all collaborators.
Where you are intending to use your saved query documents within a Task, elements to consider are:
Use fully qualified table names in SQL logic.
Adding 'drop table if exits … ' statements ahead of your CTAS statements can improve repeatability of your code.
Save the full set of query statements required into a single query document, with each statement ended with the ; character.
Remove any exploratory / analysis queries or statements which are not required for the production of the output tables.
Add comments to you query documents using the ‘--’ inline code commenting reserved characters.
Warning: Ensure output is written to the publish_db schema so that it is available as the output of a Task and accessible within a derived automated data product.
References and FAQs